本地 AI 图片视频搜索引擎——MaterialSearch
基于 AI 的本地素材搜索引擎。扫描本地的图片以及视频,可以用自然语言进行查找。
实现中文语义下的 以图搜图、截图搜视频、查找本地素材、根据文字描述匹配画面、视频帧搜索、根据画面描述搜索视频。找素材再也不用费力去一个个翻 tag 了。

文章目录
准备运行环境
首先,默认看本文的照片视频都是存在 windows 系统上的,以下都是基于 win 系统的操作
需要准备3个或4个东西
Python 3.11.7,Git ,CUDA,这三个的下载地址在文章的最前边。
视情况,你可能还需要一个魔法上网工具(假设你的魔法上网工具代理在127.0.0.1:6808)
安装 Python 3.11.7 与 pip
我这里采用直接系统内安装Python 3.11.7的方式(其实安装Python3.12.9也是可用的,看你需求了。)
如果你会用Miniconda,也可以用Miniconda实现Python多版本切换。
- 访问 Python3.11.7 下载页面
-
把页面拉到底,找到【Windows installer (64-bit)】点击下载
-
安装是注意,到这一步,需要如下图这样勾选 Add Python to PATH
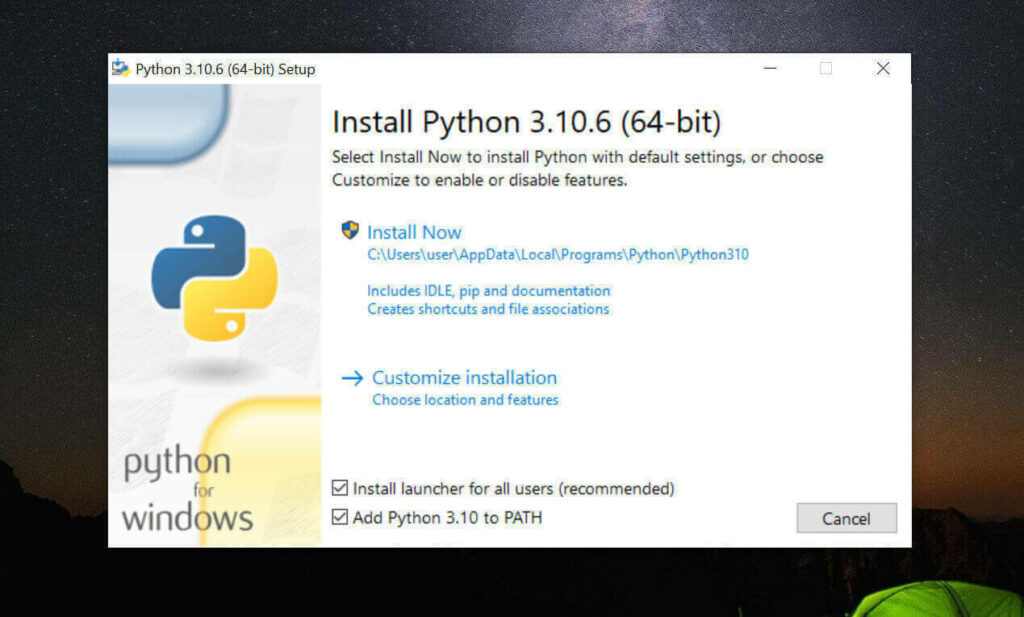
然后再点上边的 Install Now
python -
安装完成后,命令行里输入
Python -V,如果返回Python 3.11.7那就是成功安装了。 -
命令行里输入
python -m pip install --upgrade pip安装升级pip到最新版。
安装 Git
-
访问 Git 下载页面
-
点击【Download for Windows】,【64-bit Git for Windows Setup】点击下载
-
一路下一步安装
-
命令行运行
git --version,返回git version 2.XX.0.windows.1就是安装成功了。
安装 CUDA (nvidia显卡用户)
-
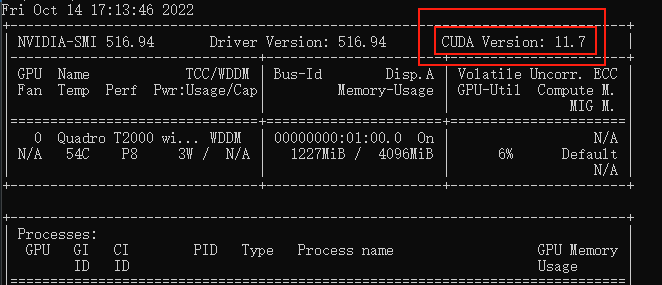
命令行运行
nvidia-smi,看下自己显卡支持的 CUDA版本
(升级显卡驱动可能会让你支持更高版本的 CUDA)
-
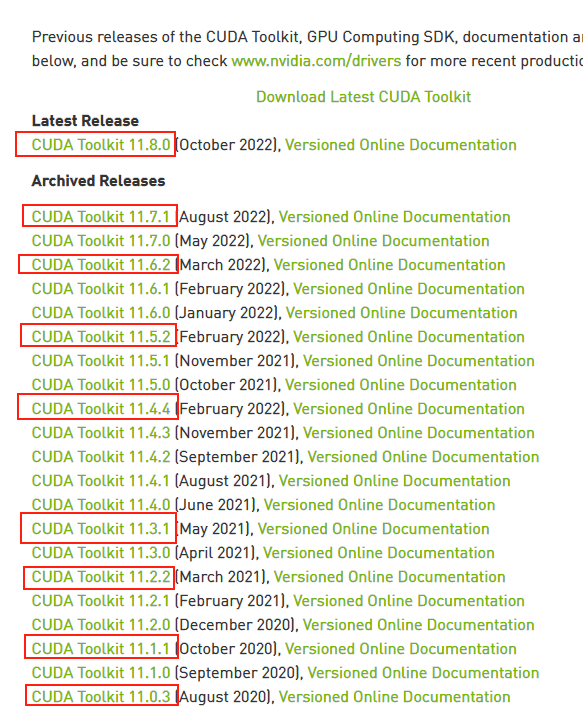
接下来前往英伟达 CUDA 官网,下载对应版本。
注意请下载,你对应的版本号最高的版本,比如我的是11.7的,那就下11.7.1(这里最后的.1意思是,11.7版本的1号升级版)
-
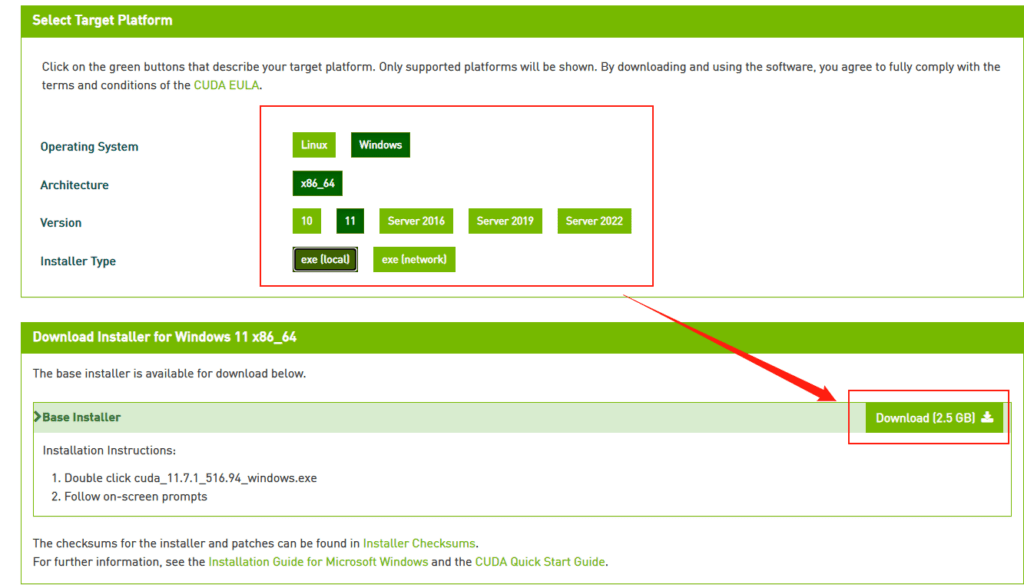
选你自己的操作系统版本,注意下个离线安装包【exe [local]】,在线安装的话,速度还是比较堪忧的。
正式安装
以下假设你当前文件目录是D:\github\,
建立虚拟环境并安装依赖
避免玩其他 Python 项目时出现项目依赖冲突问题
- 安装虚拟环境工具(virtualenv)
pip install virtualenv
pip install virtualenvwrapper
# virtualenvwrapper一定要在virtualenv后安装
- 创建一个新的虚拟环境:
virtualenv MSWenv
这将在当前目录下创建一个名为”MSWenv”的虚拟环境。
- 激活虚拟环境:
D:\github\MSWenv\Scripts\activate
这将激活虚拟环境,并将您的终端提示符更改为虚拟环境名称类似这样
(MSWenv) D:\github> ▏
拉取源码并安装依赖
# 拉取仓库
git clone https://github.com/chn-lee-yumi/MaterialSearch.git
# 进入目录
cd MaterialSearch
# 安装全部依赖(GPU运行)
pip install -U -r requirements.txt --index-url=https://download.pytorch.org/whl/cu121 --extra-index-url=https://pypi.org/simple/
# 安装全部依赖(CPU运行)
pip install -U -r requirements.txt --index-url=https://pypi.org/simple/
注意:
1. GPU运行里的cu121,作者原始脚本里这里是cu118,虽然理论上最新的是cu124,但是作者限制torch版本要小于2.4,所以实际最大只能用到CU121。
2. 如果你这会儿还拿不准用 GPU 还是 CPU 运行的话,请先按照【安装全部依赖(GPU运行)】执行,torch的GPU版本也支持CPU运行。
尝试启动
按照以下命令启动项目
python main.py
- 首次运行会自动下载模型。下载速度可能比较慢,请耐心等待。如果网络不好,模型可能会下载失败,这个时候重新执行程序即可。
- 如果想使用”下载视频片段”的功能,需要安装ffmpeg。如果是Windows系统,记得把ffmpeg.exe所在目录加入环境变量PATH,可以参考:Bing搜索。
-
如果不知道在你设备上 CPU 和 GPU 那个更快,可以在上边步骤中先走 【安装全部依赖(GPU运行)】,在依赖安装完毕后执行
python benchmark.py,运行基准测试。

正式运行MaterialSearch
MaterialSearch 配置设置
建议通过在项目根目录创建.env文件修改配置
.env文件配置示例:
# 下面添加扫描路径,用英文半角逗号分隔
ASSETS_PATH=D:\Videos,D:\Pctures
# 如果路径或文件名包含这些字符串,就跳过,逗号分隔,不区分大小写
IGNORE_STRINGS=thumb,avatar,__MACOSX,icons,cache
# 图片最小宽度,小于此宽度则忽略。不需要可以改成0
IMAGE_MIN_WIDTH=64
# 图片最小高度,小于此高度则忽略。不需要可以改成0。
IMAGE_MIN_HEIGHT=64
# 视频每隔多少秒取一帧,视频展示的时候,间隔小于等于2倍FRAME_INTERVAL的算为同一个素材,同时开始时间和结束时间各延长0.5个FRAME_INTERVAL
FRAME_INTERVAL=2
# 视频搜索出来的片段前后延长时间,单位秒,如果搜索出来的片段不完整,可以调大这个值
VIDEO_EXTENSION_LENGTH=1
# 素材处理批次大小,过大会导致显存不足而无法运行或拖慢速度。
SCAN_PROCESS_BATCH_SIZE=4
# 支持的图片拓展名,逗号分隔,请填小写
IMAGE_EXTENSIONS=.jpg,.jpeg,.png,.gif,.heic,.webp,.bmp
# 支持的视频拓展名,逗号分隔,请填小写
VIDEO_EXTENSIONS=.mp4,.flv,.mov,.mkv,.webm,.avi
# 监听IP,如果想允许远程访问,把这个改成0.0.0.0
HOST=127.0.0.1
# 监听端口
PORT=8085
# 运行模式
DEVICE=cuda
# 使用模型
MODEL_NAME=OFA-Sys/chinese-clip-vit-base-patch16
# 数据库保存位置
SQLALCHEMY_DATABASE_URL=sqlite:///./instance/assets.db
# 是否web页启用登录验证功能,如需启用改为true
ENABLE_LOGIN=False
# 登录用户名
USERNAME=admin
# 登录密码
PASSWORD=123456
# 是否自动扫描设置路径下的文件变化,如果开启,则会在指定时间内进行扫描,每天只会扫描一次
AUTO_SCAN=False
# 自动扫描开始时间
AUTO_SCAN_START_TIME=22:30
# 自动扫描结束时间
AUTO_SCAN_END_TIME=8:00
# 是否启用文件校验(如果是,则通过文件校验来判断文件是否更新,否则通过修改时间判断)
ENABLE_CHECKSUM=False
- 你发现某些格式的图片或视频没有被扫描到,可以尝试在
IMAGE_EXTENSIONS和VIDEO_EXTENSIONS增加对应的后缀。 -
小图片没被扫描到的话,可以调低
IMAGE_MIN_WIDTH和IMAGE_MIN_HEIGHT重试 -
运行模式(DEVICE)可以写的选项有auto/cpu/cuda/mps`四种,如果写 auto 的话,优先级是这样的:cuda > mps > directml > cpu
-
一般来说默认的小模型就够用了,如果你显存大或者感觉小模型的精度不够,可以改成更大的模型
更换模型需要删库重新扫描!否则搜索会报错。数据库路径见SQLALCHEMY_DATABASE_URL参数。 -
模型越大,扫描速度越慢,且占用的内存和显存越大。
如果显存较小且用了较大的模型,并在扫描的时候出现了”CUDA out of memory”,请换成较小的模型或者改小SCAN_PROCESS_BATCH_SIZE。如果显存充足,可以调大上面的SCAN_PROCESS_BATCH_SIZE来提高扫描速度。
因为目前的N卡驱动,支持了内存显存融合,超过物理显存的模型会被放在内存中,不会直接炸显存
可以启动任务管理器——性能——GPU——专用GPU内存查看实际显存占用。不要让斜杠前的数字过于接近斜杠后的数字(比如:10.7/12GB就是良好配置,而11.8/12GB就不太好了)- 4G显存推荐参数:小模型,SCAN_PROCESS_BATCH_SIZE=8
- 4G显存推荐参数:大模型,SCAN_PROCESS_BATCH_SIZE=2
- 8G显存推荐参数1:小模型,SCAN_PROCESS_BATCH_SIZE=16
- 8G显存推荐参数2:大模型,SCAN_PROCESS_BATCH_SIZE=4
- 超大模型最低显存要求是6G,且SCAN_PROCESS_BATCH_SIZE=1
- 其余显存大小请自行摸索搭配。
- 支持的模型列表
- 中文小模型:
OFA-Sys/chinese-clip-vit-base-patch16 - 中文大模型:
OFA-Sys/chinese-clip-vit-large-patch14-336px - 中文超大模型:
OFA-Sys/chinese-clip-vit-huge-patch14 - 英文小模型:
openai/clip-vit-base-patch16 - 英文大模型:
openai/clip-vit-large-patch14-336
- 中文小模型:
构建 MaterialSearch 一键启动脚本
- 目录下新建一个文件
myrun.txt - 打开填写以下内容
call D:\github\MSWenv\Scripts\activate
python main.py
pause
- 改后缀名为
myrun.bat以后启动直接运行这个文件就好了。

- 注意不要关闭那个黑乎乎的CMD窗口,不用管那行红字,那只是提示工具的web页是用的Werkzeug运行的,只要你用这个工具库就会有这个提示。
-
打开浏览器访问最后提示的
http://127.0.0.1:8085

开始使用 MaterialSearch
- 第一次使用需要先点击【扫描】按钮让程序本地素材做扫描生成数据库。
- 扫描速度,我写本文时用的 GPU 是 N卡 1650 ,大概 1图·1线程/秒。4G显存小模型可以开8线程,1小时理论可以扫2W多张图。视频处理速度大概是图片的三分之一,毕竟多了截取多个视频帧的步骤,默认是2秒一个关键帧,基本就是1小时的视频需要扫描1小时……
- 之后就可以用文字搜图,搜视频了,支持自然语言搜索,但描述请一定简单准确,毕竟用的模型参量也没那么大嘛

- 扫描图片需要的时间比较长,不过搜起来的速度还是很快的,我尝试在我的CPU:J4150,内存:8GB的 NAS 上部署,匹配阈值为0的情况下,大概1秒可以进行20000次图片匹配,如果提高匹配阈值为10,则大概可以提升到每秒大约35000次图片匹配。
- 搜视频时,如果结果中的视频很多且视频体积太大,电脑会卡。毕竟又不是剪辑工作站,一般人电脑那会同时开一堆视频的。所以建议搜索视频时,右侧那个【Top X】不要超过6个。

TeacherDu
2025-03-08 23:38
我只想要图片~
白熊阿丸
2025-03-07 05:06
这个有趣诶
Jeffer.Z
2025-03-04 13:37
硬核,我觉得更硬核的是搜索词,我电脑估计是搜出来的都是电商海报和app海报。
去年夏天
2025-03-04 15:02
不然我搜出来的都是真人照片了嘛,电脑里也就这些图可以拿出来展示了
maqingxi
2025-03-04 08:31
你这详细的教程,菜鸟可以抄作业。
去年夏天
2025-03-04 15:02
希望抄的愉快~成功部署
流放之路
2025-02-28 15:02
大佬太强了,我8G显存感觉部署了精度也没那么高
去年夏天
2025-02-28 15:15
找到符合描述的图片,这个引擎是可以做到的。
找到所有符合描述的图片,这个就不太行了,还是会漏掉一些符合描述的图片。
obaby
2025-02-28 13:08
Σ(°ロ°),这搜索引擎厉害了。
等回家部署一个,这个作业得抄啊。
去年夏天
2025-02-28 14:48
模型对真人照片的匹配度更好哦,比文章中举例用的插画要更好用。
zeruns
2025-02-28 12:28
很实用
去年夏天
2025-02-28 14:59
图多的话非常实用,不用手动给图片打标签了