近期大量个人博客被自动化繁体镜像搬运
最近陆陆续续很多个人博客被自动化繁体搬运 镜像 ,对方用多个域名,使用 CloudFlare Worker 作为基础设施,伪装为谷歌爬虫 UA ,实时反代并繁体翻译大量个人博客,积累域名 SEO 权重。
博客被恶意 镜像 不仅会影响站点的在搜索引擎的收录,排名,权重,更可能会被搜索引擎屏蔽!

[toc]
如何发现自己博客被镜像了?
- 直接谷歌搜一下自己热门文章的标题,自己博客的简介,自己博客的标题,看看有没有奇怪的繁体版结果。
- 检查访问日志,找到所有自称是 Google bot PC的流量(UA显示为
Mozilla/5.0 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)),将其与 Google 公布的爬虫 IP 段进行对比。(后期不排除他仿冒其他UA访问,比如谷歌移动UA,百度UA,必应UAE等)
博客被镜像了怎么办?
网友们大致的处理措施是这样的
一、在网站页面中添加防镜像跳转代码
(function () {
var validDomain = 'tjsky.net'; // 你的域名
var redirectUrl = 'https://www.tjsky.net'; // 重定向链接
var hostname = document.location.hostname;
function createWatermark(text) {
var watermarkDiv = document.createElement('div');
watermarkDiv.style.pointerEvents = 'none';
watermarkDiv.style.position = 'fixed';
watermarkDiv.style.top = '0';
watermarkDiv.style.left = '0';
watermarkDiv.style.width = '100%';
watermarkDiv.style.height = '100%';
watermarkDiv.style.zIndex = '9999';
watermarkDiv.style.opacity = '0.1';
watermarkDiv.style.background = 'transparent';
watermarkDiv.style.overflow = 'hidden';
watermarkDiv.style.display = 'flex';
watermarkDiv.style.justifyContent = 'center';
watermarkDiv.style.alignItems = 'center';
watermarkDiv.style.flexWrap = 'wrap';
var watermarkText = document.createElement('div');
watermarkText.innerText = text;
watermarkText.style.color = 'black';
watermarkText.style.fontSize = '30px';
watermarkText.style.transform = 'rotate(-30deg)';
watermarkText.style.whiteSpace = 'nowrap';
watermarkText.style.margin = '20px';
for (var i = 0; i < 100; i++) {
watermarkDiv.appendChild(watermarkText.cloneNode(true));
}
document.body.appendChild(watermarkDiv);
}
if (hostname !== validDomain) {
createWatermark(validDomain); // 给页面加上前边设置的域名为水印
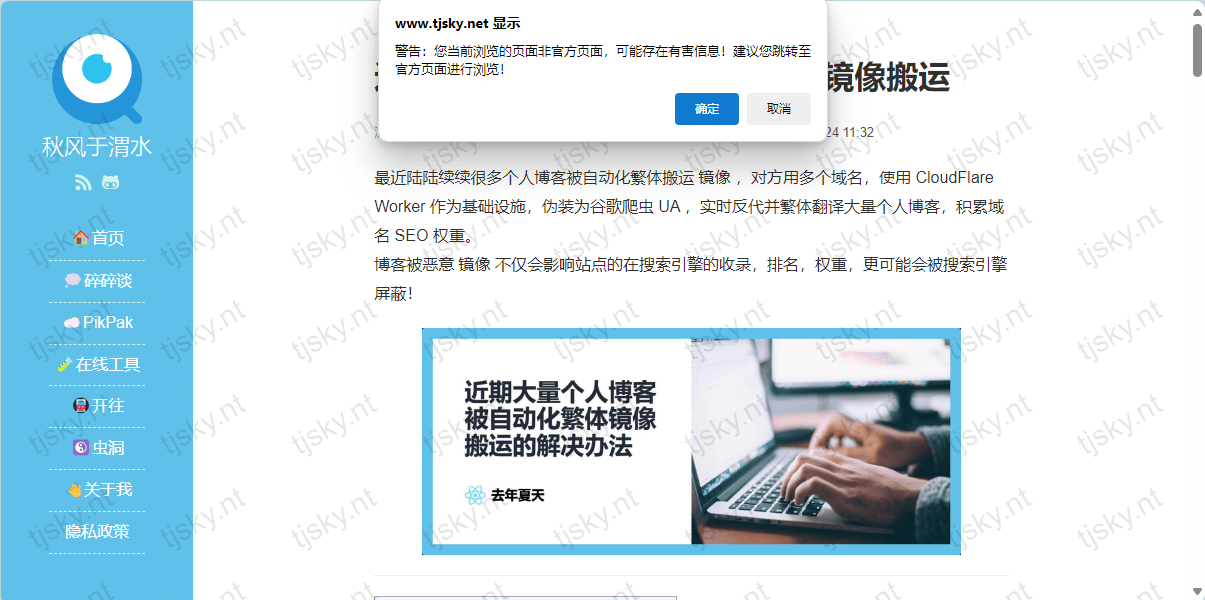
var userResponse = confirm("警告:您当前浏览的页面非官方页面,可能存在有害信息!建议您跳转至官方页面进行浏览!");
if (userResponse) {
window.location.replace(redirectUrl);
}
}
})();
这个代码的目的是,利用对方会无脑反代一切内容的机制,在所有页面内都插入检测 JS 代码,在网友访问时,检测当前域名是否为所设定自己博客的域名,如果不是所设定的博客域名则在网站背景中嵌入带域名水印并使用 confirm() 打断页面渲染,并弹出弹窗警示用户跳转回源站。
并且使用 JavaScript 动态插入水印 div 并不设置 id,class 等标识,防止对方通过u正则表达式匹配删除特定 div 元素。
反镜像代码触发时的效果示意
但是这里有几个问题
1. 域名和跳转链接为明文,对方可以自动化匹配
2. JS代码也为明文,对方可以检测到发生跳转自动化打断跳转执行。
解决办法很简单:使用 JavaScript 混淆,并将这段JS拼接到站点关键JS块内
让对方无法匹配到代码,而对方如果完全阻止JS,则会导致页面出现严重的渲染(比如部分样式通过JS来动态引入,而不是直接写在CSS里)问题。
至于怎么混淆这个工具就很多了,简单谷歌一下就有很多工具可用,比如这个和那个。
这里注意三个点
1. 记得勾选 Unicode 转义,不然后面的中文提示还是原文
2. 字符串加密方式可以选RC4这个相对base64不太常见的编码方式,加密密度选1(既所有都加密混淆)
3. 混淆会拖累执行性能,在保证加密混淆的前提下,尽可能混淆程度低一点。
二、阻止非验证的谷歌爬虫访问
有些安全插件,防火墙具有验证谷歌爬虫的选项,会对声明为谷歌爬虫的访问做 DNS 反查,确定爬虫访问 DNS 掩码符合谷歌公布的掩码,并且归属为谷歌公布的爬虫 IP 段才会允许爬取。
三、向域名注册商报告滥用
镜像他人网站是明显的恶意滥用行为,可以向对方的域名注册商投诉。
四、向CloudFlare报告滥用
对方时用的域名托管商和代码执行基础设置都是CloudFlare:举报页面
五、向域名的注册局报告滥用
一些被滥用比较多的域名比如.top是有滥用举报的,举报页面
六、向谷歌申请移除镜像站的搜索结果
因为它会原样照搬反代网页,那其实你可以通过HTML 标记验证方式在 Google Search Console 里把他的反代域名也认证到你自己名下,然后在Google Search Console 向谷歌申请移除搜索结果
七、在后端反制一下?
评论区给了我一个很好的提醒,既然他是通过特定IP和非谷歌归属IP的特定UA来抓取反代的,
其实你可以通过 nginx.conf 实现一些好玩的效果,比如只要 UA 显示为谷歌 PC bot,但 IP 段不在谷歌公布的 IP 段内,或者某指定 IP 访问时,就301跳走,返回特定页面,反代其他网站页面,在原始网页中加mu料ma。
以下仅为抛砖引玉,各位大佬可以开发更有意思的方式。
- 当抓取服务器
154.39.149.128(这是目前他的抓取服务器 IP )访问时,自动跳转到百度首页(百度首页只是个例子,你可改成其他奇 wei 怪 gui 的网站。实现让他的域名被降权或出现违规而被禁止)
server
{
listen 80 XXXXXXXXXXX;
listen 443 XXXXXXXXXX;
server_name XXXXXXXXXXX;
index XXXXXXXXXXX;
root XXXXXXX;
#一般将下方代码按自己需求修改后,插入在你网站上边这一坨配置的后面就行
#指定IP访问自动反代百度网页
if ($remote_addr = 154.39.149.128) {
proxy_pass http://www.baidu.com;
}
#指定IP访问自动反代百度网页结束
#你网站的其他配置
}
- 当UA显示为谷歌PC爬虫,但访问IP不在谷歌公布的IP段时,反代其他网页给他。
- 首先在谷歌获取json格式的IP段列表:爬虫 IP 段
- 然后将其转化为类似这样的格式(可以让 AI 帮你搞)
34.165.18.176/28 1; 192.178.5.0/27 1; 34.126.178.96/28 1; - 放在nginx可以访问的地方,比如
/usr/local/nginx/conf/firewall.conf -
修改nginx.conf
# 加载 IP 白名单文件
geo $blocked_ip {
default 0;
include /usr/local/nginx/conf/firewall.conf;
}
# 检查特定 User-Agent 的访问
map $http_user_agent $is_special_ua {
default 0; # 0,表示不匹配
"~*Mozilla/5.0 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)" 1; # 指定爬虫UA
}
#将上方代码按自己需求修改后,插入在你网站下边这一坨配置的前面就行
server
{
listen 80 XXXXXXXXXXX;
listen 443 XXXXXXXXXX;
server_name XXXXXXXXXXX;
index XXXXXXXXXXX;
root XXXXXXX;
#将下方代码按自己需求修改后,插入在你网站上边这一坨配置的后面就行
#符合UA但不符合IP段时自动反代指定网页
if ($is_special_ua = 1) {
if ($blocked_ip = 0) {
proxy_pass http://www.baidu.com;
}
}
#符合UA但不符合IP段时自动反代指定网页结束
#你网站的其他配置
}
吐槽
为啥我的这个主站没有被搬运,我另一个访问量很低的(日均PV只有几十),内容也比较无聊的在国内的站反而被他搬走了。
- 可能原因一:貌似对方不会镜像使用境外服务器的非备案站点。
-
可能原因二:他的访问因为没通过谷歌爬虫检查,被拦住了。
- 对方只搬运流量相对小一点的站,以免被发现。
事态更新
- 2024-07-18:第一次知道有人网站被镜像
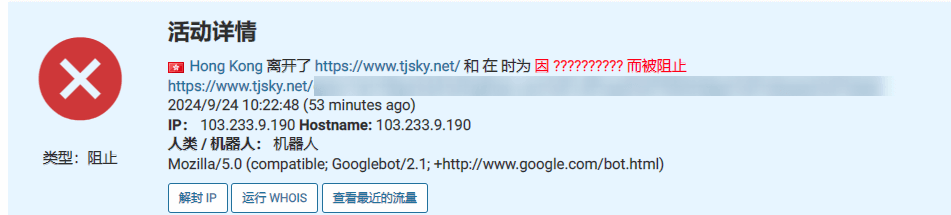
- 2024-08-20:服务器后端被拦截中出现镜像者所使用的IP:
154.39.149.128,php 探针都没删。 - 2024-08-28:镜像服务器迁移到:
103.233.9.190,这次学精了,隐藏 PHP 控制台,设置了 IP 区域限制,只有非中国大陆IP访问才会正常显示内容。 - 2024-09-05:他的服务器一度被人打到宕机
- 2024-09-24:看到被镜像的人越来越多固有此文
- 2024-10-09:增加两种基于 nginx 的反制措施思路
参考资料
网站被恶意镜像了该怎么办
我的个人博客网站再次被恶意镜像,这次手段高明了许多
网站被恶意镜像——如何保护博客流量及预防
保护您的博客不被恶意镜像
我的博客也有一天会被反代?
我的博客被完整地反向代理,并自动翻译成了繁体中文

非猪
2025-01-09 12:11
发现我被两个人镜像了…
leeorz
2024-10-28 01:27
好像是那种做黑帽SEO的,先养站群,然后给自己的站做反链,提高自己站的权重。
这种方式有蛮多其实都是国内的人在玩.
因为简中流量在广告网络不值钱,同时有可能因为肉身在国内,怕站内的某些内容惹麻烦,所以他们专门屏蔽简中的流量,专做繁中的流量,他们甚至屏蔽了国人常见的翻墙落地ip,比如香港阿里云。
典型的两个内容农场看起来像这种手法,一个是 kknews点cc,另外一个是read01点com
这俩站典型的垃圾站,之前还看到有人专门向google举报,但这俩站就是一直不倒,流量来源大部分也是google
去年夏天
2024-10-28 09:23
google基本是放弃对简中的黑SEO防御的(不过其实繁体也做的不怎么样)
石樱灯笼
2024-10-09 17:26
随便搜了一下,在谷歌搜到一个镜像结果,直接点进去是404,但是如果用国外IP访问的话,是一个繁体版本的我的博客。
盯了一下access.log,同样是103.233.9.190,看来是同一个人。
检查了一下域名,是2023年被谷歌收录的域名,用wayback看了下,只有去年11月至今年4月份的记录,域名看起来像个垃圾站。
我现在在考虑用一点好玩的办法搞他。
去年夏天
2024-10-09 18:10
比如,来点只有他能抓取到的违规内容让他域名降权,或者既然是繁体版就来点针对性的有害内容等待台湾警方抓他。能折腾他的方式还是挺多的
石樱灯笼
2024-10-09 19:11
我搜了一下,这个人是惯犯了,常年镜像他人网站,103.233.9.190只是今年启用的一个IP而已。这人手底下的域名数量很庞大,可以推断出Cloudflare举报和DMCA举报都没啥用。
主要还是谷歌现在是废物了。2008年那阵,垃圾站和镜像站也是门赚钱的大生意,但是谷歌改进算法之后,垃圾站和镜像站基本全灭了,安心了十多年,现在谷歌竟然识别不出来是镜像站,不仅收录了,有些还比源站排名还高。谷歌是完犊子了。
去年夏天
2024-10-09 20:04
谷歌看起来已经基本放弃简体中文搜索了…他用了一些同义词和本地化替换洗稿,所以有可能他替换词反而导致排名更高。
去年夏天
2024-10-09 22:28
可以通过 HTML 标记验证方式在 Google Search Console 里把他的反代域名也认证到自己名下,然后就好办了。
石樱灯笼
2024-10-09 22:30
不行,那样容易被反杀。
石樱灯笼
2024-10-10 10:15
仔细想了一下也不是不可以,用麻烦一点的小办法就没有风险了。我用的文件验证,除了这个Google Search Console 认证文件之外,其他的请求我都直接在cloudflare那一层把请求重定向到有趣的网站上去了。
Google Search Console 认证之后要等一天才能看结果,也是蛮慢的。也没啥用,Google 的抓取结果,至少首页已经变成重定向之后的网站了。
去年夏天
2024-10-10 10:17
谷歌的抓取频率比较不好说。感觉这样可以申请更新索引,能快一点变化?
石樱灯笼
2024-10-10 10:30
放着不管就好了。我现在写的文章,谷歌都不太愿意收录。就算收录了也没啥效果,文章内容经济价值一般,没有什么引流的关键字,搜不到。
现在浏览量基本全是靠RSS订阅或者评论回访来的(我猜的,我没有做浏览统计),而且这几年老读者也全都去沉迷短视频了,80%的老读者(包括他们的博客)都消失了,算是中文互联网末期了,爱咋咋地吧。
去年夏天
2024-10-10 23:28
我这博客百度完全不收录(严格说是抓了,但是搜索结果里不展示),必应和谷歌的自然搜索占了一半以上来源,RSS订阅+评论回访+被引用来的也就占了十分之一吧。
石樱灯笼
2024-10-11 15:07
都一样。百度扫了,也抓了,但是老文章按关键字搜索的话,是不显示的,必须全标题才能搜索,这就没意义了。最近几年的新文章则是完全不收录。偶尔还会出现百度把整站都删了的情况(用site:搜不到)。
必应的不知道。
谷歌来源的话看Search Console的「效果」可以说惨不忍睹。
很早之前我就把统计功能删了。最早期用CNZZ后来发现数据非常的不准确(因为百度和谷歌都改了跳转方式),然后CNZZ还不停的要手机号。删了之后也再没找过其他统计功能,看着烦。所以统计数据什么来源什么都是凭感觉,基本都是靠评论量估计出来的。新人评论基本没有,老人也很少有主动评论的(所以RSS订阅不好),多数评论都是评论回访(你不理他他不理你这种)。
爱咋咋地吧。
去年夏天
2024-10-11 15:12
我就是百度用
site:tjsky.net都搜不到任何文章的那个 :laughing:石樱灯笼
2024-10-23 18:35
你试试我我的域名(不带www,或者搜blog的二级域名)在谷歌上用site搜。我人都傻了。
去年夏天
2024-10-23 18:50
我也傻了……这啥子个情况……
Teacher Du
2024-10-04 22:09
我也写了一篇解决教程,不过没有你的这个详细!
去年夏天
2024-10-06 19:40
看到啦,写的简略但是措施很全呀
klcdm
2024-10-02 16:42
忘记了,收藏一下,虽然不太懂实现的方法不过有空可以去打一针预防针
网友小宋
2024-09-26 11:15
或许上因为你那个站点内容比较真实,更新稳定。
去年夏天
2024-10-09 21:46
我怀疑只是单纯因为站点的IP在国内
去年夏天
2024-10-09 21:59
经过一番研究,可以确定是因为:他的伪装为谷歌爬虫的访问没通过安全插件的谷歌爬虫检查,被拦住了。
Limour
2024-09-26 09:19
通过 shynet 追踪 Referrer,发现我也是受害者😂
Liudon
2024-09-25 12:03
我的也被镜像了 😅
竹林里有冰
2024-09-25 01:10
受害者前来报到
去年夏天
2024-09-25 08:44
你应该是我最早看到涉及这个事件的人了,开始我还以为是少数个例,结果最近被镜像翻译洗稿的越来越多
ACEVS
2024-09-24 17:59
网友小宋就中招了。
白熊阿丸
2024-09-24 17:02
简直了,博客都有人惦记,防不胜防
去年夏天
2024-09-24 17:18
而且看起来特意选比较小的博客做搬运
诺多
2024-09-24 14:24
我的站也是,前段时间被直接镜像,不知道它到底这么干是为啥。
去年夏天
2024-09-24 14:35
应该是为了快速积累域名SEO权重。已经有大佬扒出来,核心代码应该是个搞内容农场的人开发的。
老张博客
2024-09-24 14:03
自己小破站,目前安全。
去年夏天
2024-09-24 14:18
所以我怀疑他就设计的不镜像国外的站点。
涛叔
2024-09-24 12:19
要我说没有必要管,也管不过来。
多输出内容,形成自己的风格,表达自己的观点,让人看到内容就联想到原作者。
如果能达到这样的效果,被「转载」也不一定是坏事。
技术手段封禁只能算猫鼠游戏,不完没了~
去年夏天
2024-09-24 14:17