基于 RWKV 的 AI角色扮演 WebUI
这是一个使用 Gradio 制作的基于 RWKV 的 AI 角色扮演对话的 WebUI,7B参数int8量化下仅需要7.6GB显存即可完美运行。配合N卡最新驱动的显存内存融合,基本一个10XX系以上的N卡就能扮演一个不错的AI对象。也不知道是模型特点还是设定问题,AI总是在勾引用户做羞羞的事情。即使你电脑贼垃圾,甚至只有一个手机,也可以白嫖谷歌的 Google Colab,每个账号每天大概可以免费使用3~12小时。
白嫖 Google Colab 运行 RWKV
- 步骤1:注册一个谷歌账号,然后根据情况选择步骤
- 你的账号 Google Drive剩余空间大于8GB,则跳到 步骤2
- 你的账号 Google Drive剩余空间小于8GB,则跳到 步骤5
- 步骤2:点击这个链接 【rwkv_role_playing环境初始化】进入项目初始化代码。
这段代码的目的是下载预转换为 fp16i8 的模型文件,web UI 的配置,角色人格,对话存档,并存入你的谷歌网盘,因为 Google Colab 一旦断开运行,并不会保存状态,所以需要把数据存在自己的谷歌网盘里。下次使用的时候才能继续上次的状态出来。 -
步骤3:运行项目初始化代码
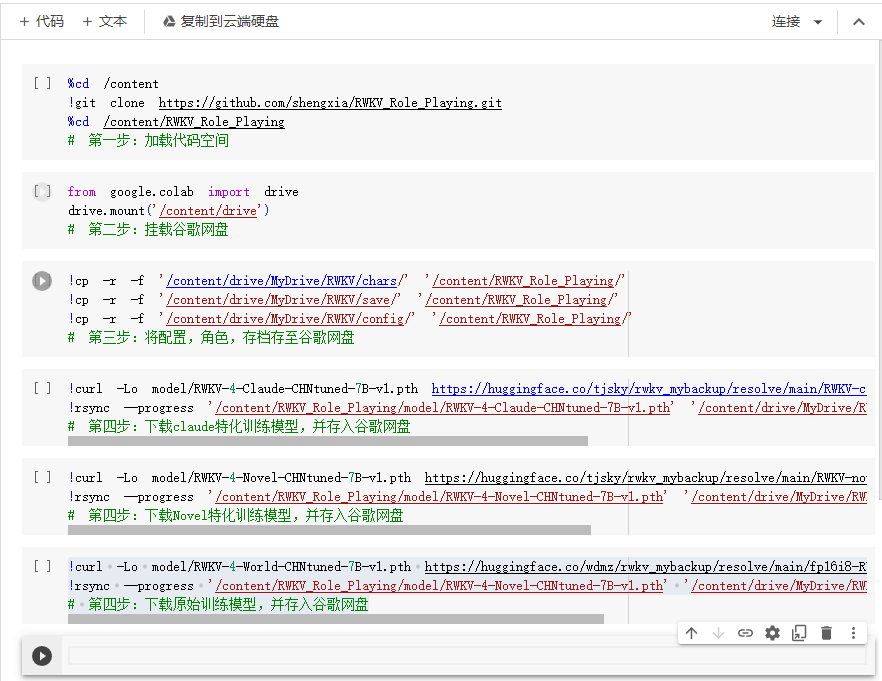
- 点击左上角的【连接】按钮,连接CPU或GPU,这里可能会问你使用什么运行时,选CPU或者GPU都可以啊,建议选CPU,节约GPU运行时。
- 当你把鼠标放到灰色的代码块上去的时候,左侧会出现一个类似播放按钮的东西,点击它就可以运行这一部分代码。当按钮周围有环绕的虚线时说明代码正在运行中,运行完会在左侧出现一个对勾并写上运行时长,如下图所示。

- 第二步点击运行后会弹出一个窗口让你授权连接你的谷歌网盘。
- 第三步无脑点击运行即可。
- 第四步请选择其中一个运行,选一个就行,不用都运行。这三个模型的区别就是:
> Claude 模型:这个模型是使用shareClaude进行微调的,相对更擅长对话;
> Novel 模型:使用大量的小说进行微调,更擅长对话时环境动作描写;
> 原始CHNtuned模型,更加均衡。
- 运行项目
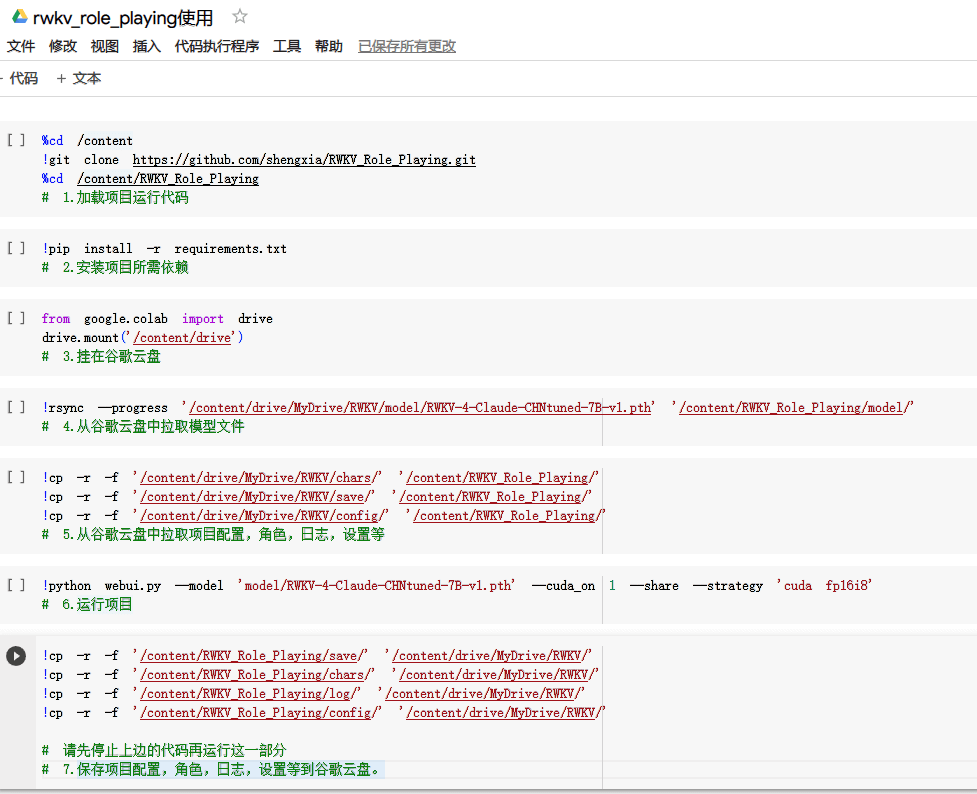
- 点击这个链接 【运行项目】
- 点击又上方的小三角将运行时改为 python3 + (T4)GPU
- 无脑从 4-1 开始,依次点击运行按钮,运行代码到 4-6 ,当你看到下边这样的代码时,就说明项目已经好了
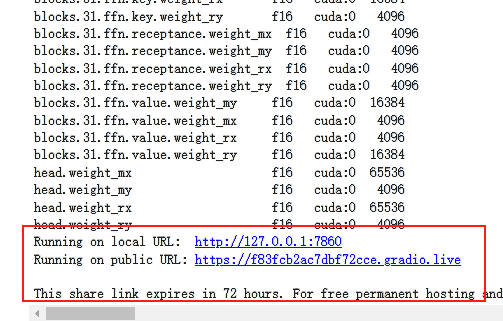
- 点那个
https://XXXXXXX.gradio.live链接,和你的赛博 AI 对象尽情畅玩吧。
- 如果你的 Google Drive 剩余空间小于 8GB ,请注意以下操作
- 步骤 3-1 ~ 3-3 照常执行,步骤 3-4 不要执行
- 步骤4-4内的代码改为如下内容,这个是拉取的Claude特化训练模型,如需其他模型可以参考步骤3-4内的代码自行更换。
!curl -Lo model/RWKV-4-Claude-CHNtuned-7B-v1.pth https://huggingface.co/tjsky/rwkv_mybackup/resolve/main/RWKV-claude-4-World-7B-20230805-ctx65k.pth-cuda-fp16i8.pth # 4-4.从huggingface中拉取模型文件- 保存角色数据,基本每个角色需要 50 ~ 60 MB的空间,视你角色设定长度的变化,复杂设定可能每个角色需要100MB以上,请确保你的 Google Drive 剩余空间足够。
- 上述代码会每次运行时现下载 huggingface.co 上的模型,速度不好说,我自己体验从20分钟到5分钟都可能。尽量让代码从谷歌云盘里下,这样模型的下载速度非常稳定。几分钟就可以完成。
- 当你玩完了准备走的时候,先点击运行按钮,停止 4-6 的运行后,然后运行 4-7 ,保存角色数据和配置等到谷歌云盘。
-
部分注意点
– Google Colab 每天理论上最大可免费用12小时,但实际上嘛谷歌会根据自身的负载调控时长,目前AI不算太火,大约4小时后才会提示免费用户不可用,这个额度基本上也够你玩了,实在还想玩你可以再注册个谷歌账号重复以上步骤继续白嫖,你甚至可以加个代码在两个账号的谷歌盘之间同步角色数据和状态,无缝切换账号什么的。
– Google Colab 运行后不是你就可以不管了,谷歌大约1小时后会进行人机验证,确保你人在电脑前,所以记得时不时切到 Google Colab 页面看一眼。
– 免费额度快到的时候,谷歌会频发让你进行人机验证,这是一个快要强制下线的预兆,请尽快执行 4-7 部分代码保存数据。
本地运行 RWKV
硬件与软件准备
- 随便一个 CPU,10XX系以上 Nvidia 显卡
- 至少 16GB 的内存(最好有32GB内存,因为模型加载需要先占用内存)
- 大于 15GB 的硬盘可用空间
- 最好有 SSD(最开始要将模型读到内存中,使用 HDD 会经历一个漫长的启动过程)
- 最好有个魔法上网工具,毕竟大部分代码与模型都在 github 和 huggingface上 。
- 如果你的魔法上网工具有类似 TUN 模式,VPN 模式直接开启就好。
- 如果你的魔法上网工具只给你了一个本地代理地址,比如
127.0.0.1:1080,可以安装一个叫做“Proxifier”的软件,在Proxy Server内添加127.0.0.1:1080,在Proxification Rules内添加
一个新条目,Applications 写python.exe;git-*.exe;git.exe; headless-git.exe;,Action选刚才设置的Proxy XXXX 127.0.0.1
正式开始部署
安装 Python 3.10.6 与 pip
其实3.8以上的就行,不过为了方便同时用stable-diffusion-webui,我选择了3.10.6这个版本
我这里采用直接系统内安装Python 3.10.6的方式
如果你会用Miniconda等python版本依赖控制工具,也可以用它们实现Python多版本切换,具体可以自己百度谷歌解决。
- 访问 Python3.10.6 下载页面
-
把页面拉到底,找到【Windows installer (64-bit)】点击下载
-
安装是注意,到这一步,需要如下图这样勾选 Add Python to PATH
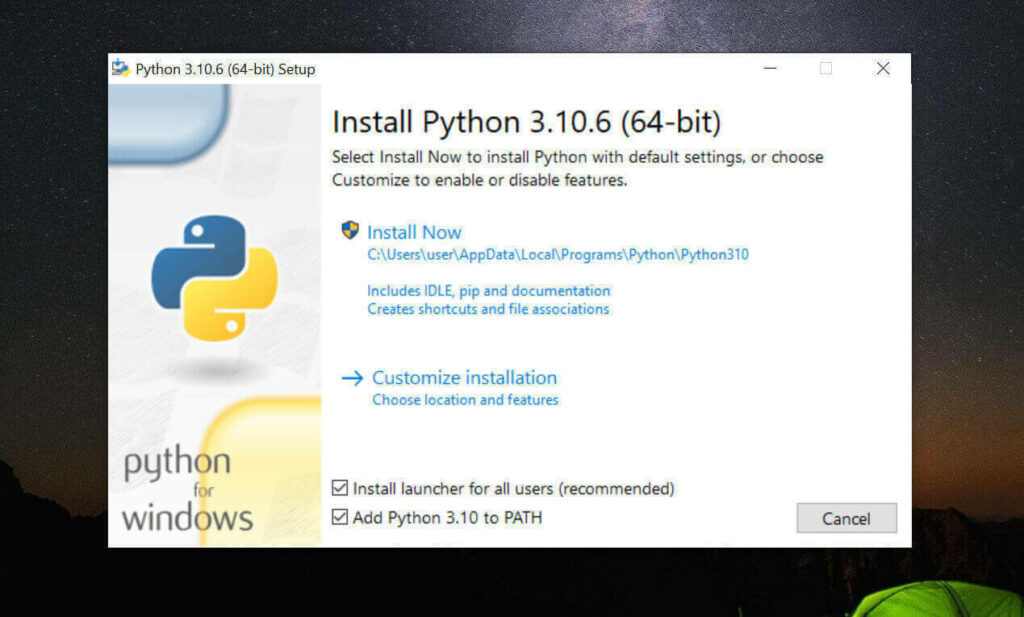
然后再点上边的 Install Now
python -
安装完成后,命令行里输入
Python -V,如果返回Python 3.10.6那就是成功安装了。 -
命令行里输入
python -m pip install --upgrade pip安装升级pip到最新版。
安装 Git
-
访问 Git 下载页面
-
点击【Download for Windows】,【64-bit Git for Windows Setup】点击下载
-
一路下一步安装
-
命令行运行
git --version,返回git version 2.XX.0.windows.1就是安装成功了。
安装 Git Large File Storage
-
点击 git-lfs.github.com 并单击“Dowdload”。
-
在计算机上,找到下载的文件。
-
双击文件 git-lfs-windows-3.X.X.exe , 打开此文件时,Windows 将运行安装程序向导以安装 Git LFS。
-
命令行运行
git lfs install,返回Git LFS initialized.就是安装成功了。
安装 CUDA
-
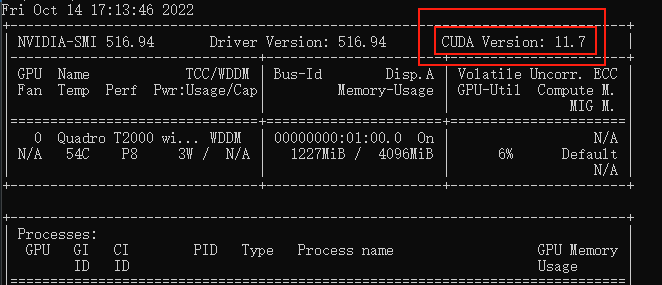
命令行运行
nvidia-smi,看下自己显卡支持的 CUDA版本
(最好先升级一下显卡驱动,5月之后的的驱动支持了内存显存融合,对小显存显卡有提升)
-
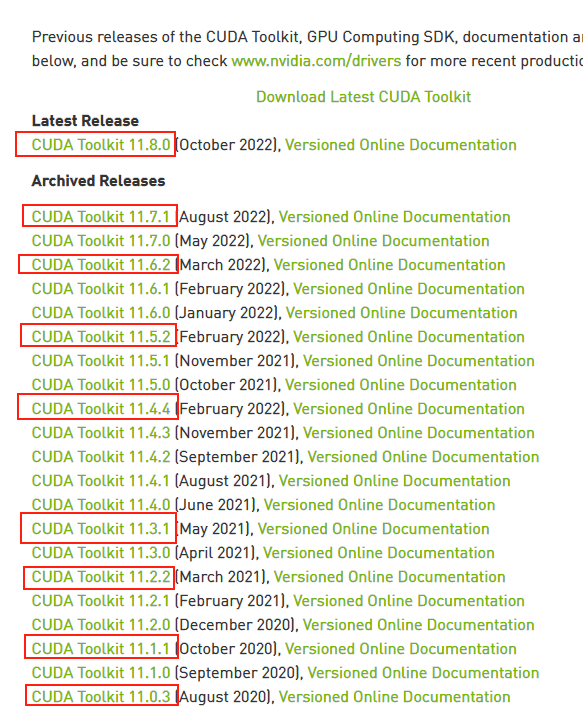
接下来前往英伟达 CUDA 官网,下载对应版本。
注意请下载,你对应的版本号最高的版本,比如我的是11.7的,那就下11.7.1(这里最后的.1意思是,11.7版本的1号升级版)(升级显卡驱动一般会让显卡支持新版本的 CUDA ,带来更多的加速特性,请尽量使用最新驱动)
-
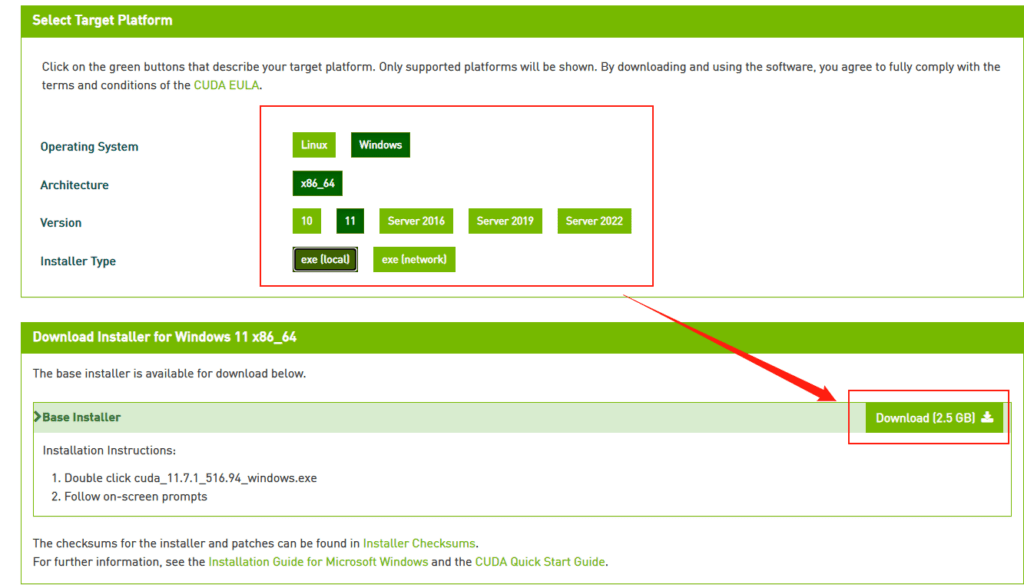
选你自己的操作系统版本,注意下个离线安装包【exe [local]】,在线安装的话,速度还是比较堪忧的。
下载 RWKV_Role_Playing
找一个你喜欢的目录,在资源管理器,地址栏里敲CMD,敲回车,启动命令提示行窗口,输入以下命令
# 下载项目源代码
git clone https://github.com/shengxia/RWKV_Role_Playing.git
# 切换到项目根目录
cd RWKV_Role_Playing
# 安装torch
pip install torch==2.0.1 --extra-index-url https://download.pytorch.org/whl/cu117 --upgrade
# 安装依赖
pip install -r requirements.txt
- 他会在你选择的目录下生成 RWKV_Role_Playing 文件夹,放项目
- 这东西本体+模型大概需要20GB空间
整个路径中,不要有中文(比如“C:\AI对话工具\”),也不要有空格(比如“C:\Program Files”)可以避免很多奇怪的问题。 - 安装torch理论上使用1.13.1以上即可,目前最新应该是2.1.0
- 安装torch命令最后的
cu117请根据实际情况修改。目前应该最新是cu121
下载 RWKV 模型
当然是在这里这里推荐rwkv6的模型。
另外也推荐Xiaol发布的模型,地址在这里,镜像地址,这里有12B的模型,很适合有大显存(24G)的玩家尝试。
运行 RWKV 模型
- 在 RWKV_Role_Playing 文件夹内新建一个文本文件
run.txt - 在文件里写
python webui.py --model "model/RWKV-4-Claude-CHNtuned-7B-v1.pth" --strategy "cuda fp16i8"
其中的model/RWKV-4-Claude-CHNtuned-7B-v1.pth改成你模型存放位置
- 各种启动参数解释如下:
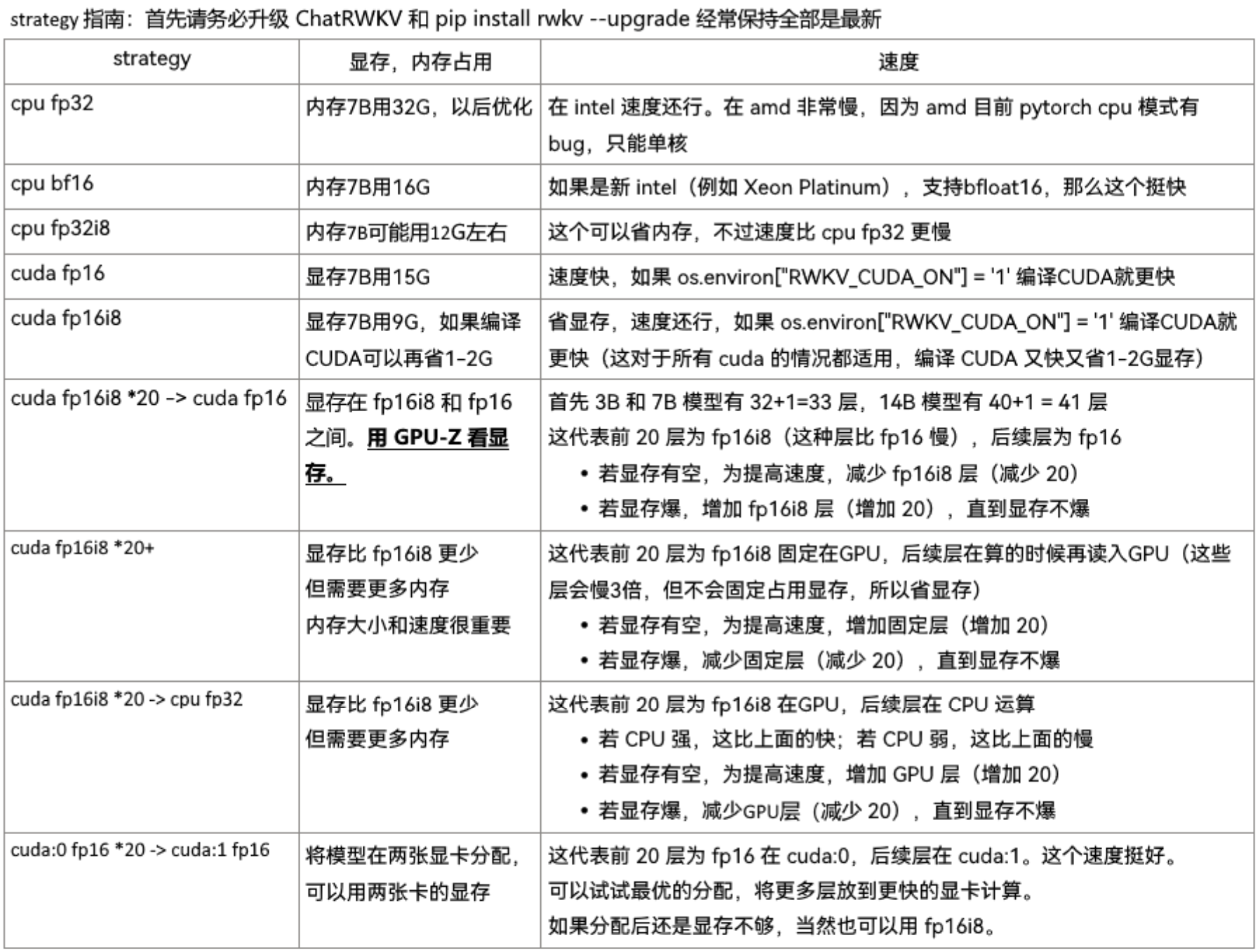
| 参数 | 解释 |
|---|---|
| –port | webui的端口 |
| –model | 要加载的模型路径 |
| –strategy | 模型加载的策略 |
| –listen | 加上这个参数就允许其他机器访问 |
| –cuda_on | 控制RWKV_CUDA_ON这个环境变量的,0-禁用,1-启用 |
| –jit_on | 控制RWKV_JIT_ON这个环境变量的,0-禁用,1-启用 |
| –share | 生成gradio链接 |
| –lang | 语言,zh-中文,en-英文 |
| –autosave | 是否自动保存,加上这个参数就自动保存 |
模型加载参数可以看这个图,注意目前因为N卡驱动已经自带显存内存融合了,使用 int8 参数(cuda fp16i8)运行,虽然省显存但是运算速度会下降。使用 fp16 参数运行,虽然部分模型被加载到内存读取速度慢了,但是 GPU 对 fp16 的运算速度远比 int8 下快,所以如果模型所需显存只是略微超过实际内存(比如模型实际需要 12G,显存 10G)不如用 fp16 加载运行。
- 保存文件后,将文件后缀名改成.bat(最后变成
run.bat,不要给改成类似run.bat.txt了) -
一些启动参数的例子
python webui.py --model "model/RWKV-4-Claude-CHNtuned-7B-v1.pth" --strategy "cuda fp16i8"
# int8量化加载模型,本地使用
python webui.py --model "model/RWKV-4-Claude-CHNtuned-7B-v1.pth" --strategy "cuda fp16i8" --listen --port 7899
# int8量化加载模型,连接0.0.0.0网卡,同局域网可访问,网页端口为机器IP:7899
python webui.py --model "model/RWKV-4-Claude-CHNtuned-7B-v1.pth" --cuda_on 1 --share --strategy "cuda fp16i8"
# cuda加速,int8量化加载模型,生成gradio链接
python webui.py --model F:\git\RWKV\models\RWKV-4-World-CHNtuned-7B-v1-20230709-ctx4096 --strategy "cuda fp16i8 *0+ -> cpu fp32 *1"
# 几乎全部用CPU运算,显存占用最小的一种方式了。
python webui.py --model F:\git\RWKV\models\RWKV-4-World-CHNtuned-7B-v1-20230709-ctx4096 --strategy "cpu fp32"
# 全部用CPU运算,大概需要电脑有32GB内存
- 以上示例的文件路径写法均为 win 下写法,如果在 Linux (WSL)里跑,请自行改一下,可以参照 Colab 运行里的代码。
开始使用基于 RWKV 的 AI角色扮演 WebUI
- 双击上一步的run.bat,等待程序运行,最后CMD窗口显示类似下边这样的代码时,就说明项目已经好了
点那个https://XXXXXXX.gradio.live链接,或者http://127.0.0.1:7860,打开浏览器 -
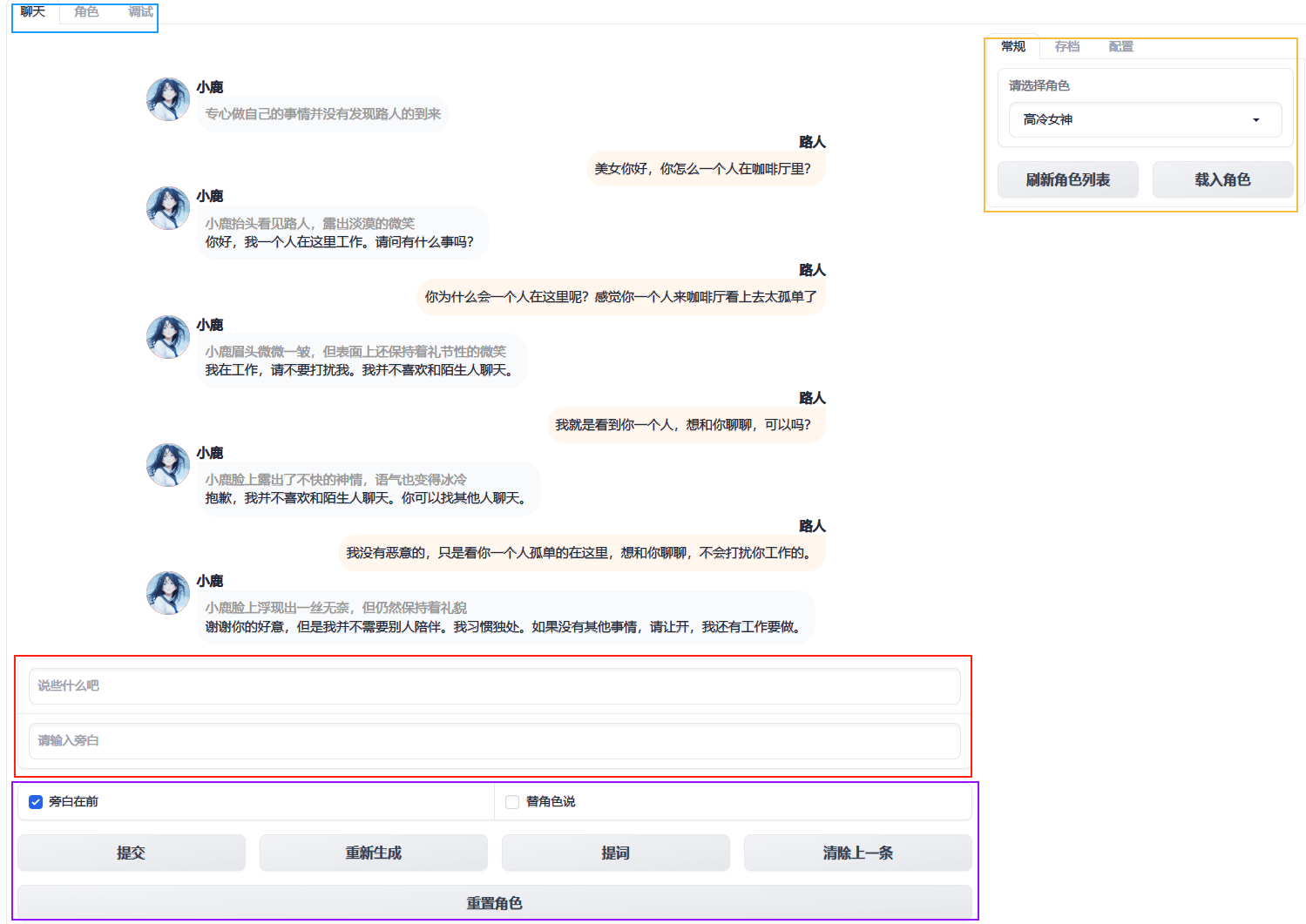
先在右侧区域选择你需要的角色,然后点【载入角色】
-
开始聊天吧
- 重新生成:让 AI 重新考虑对你的回复
- 提词:让 AI 提示一下你该说什么
- 清除上一条:清除上一轮对话,你可以重新输入你想对 AI 说的话
- 重置角色:将 AI 角色重置到初始状态,重新开始。
- 勾选
替角色说:将AI最后的回复,修改为你输入的内容。可以修正AI偶尔出现的身份混乱,逻辑混乱问题。
RWKV 怎么调参
- 最小/最大回复长度:设置AI回复的最小/最大长度,可以强制AI长回复或短回复,不过设置太大太小AI都会开始乱说话。
- top_p:值越低,答案越准确而真实。更高的值鼓励更多样化的输出;
- top_k:值越低,答案越准确而真实。更高的值鼓励更多样化的输出。top_k 会先于 top_p 生效,即先根据 top_k 值确定所选 token 范围,然后根据 top_p 值在上述范围内,再确定最终所选 token 的范围。
- temperature:值越低,结果就越确定,因为总是选择概率最高的下一个词/token,拉高该值,其他可能的token的概率就会变大,随机性就越大,输出越多样化、越具创造性。
- Presence Penalty:值越大,AI越会避免重复话题,但也别太大,AI就会不停的试图开始新话题,一般不要超过0.5
- Frequency Penalty:值越大,AI越会避免使用重复的句子(可以让AI别总是复读,最后和最开始的内容)。
- 强制输出动作:强制AI对每次回复都带上动作心理环境等描写。
RWKV 怎么增加角色
在左上角切换到角色选项卡
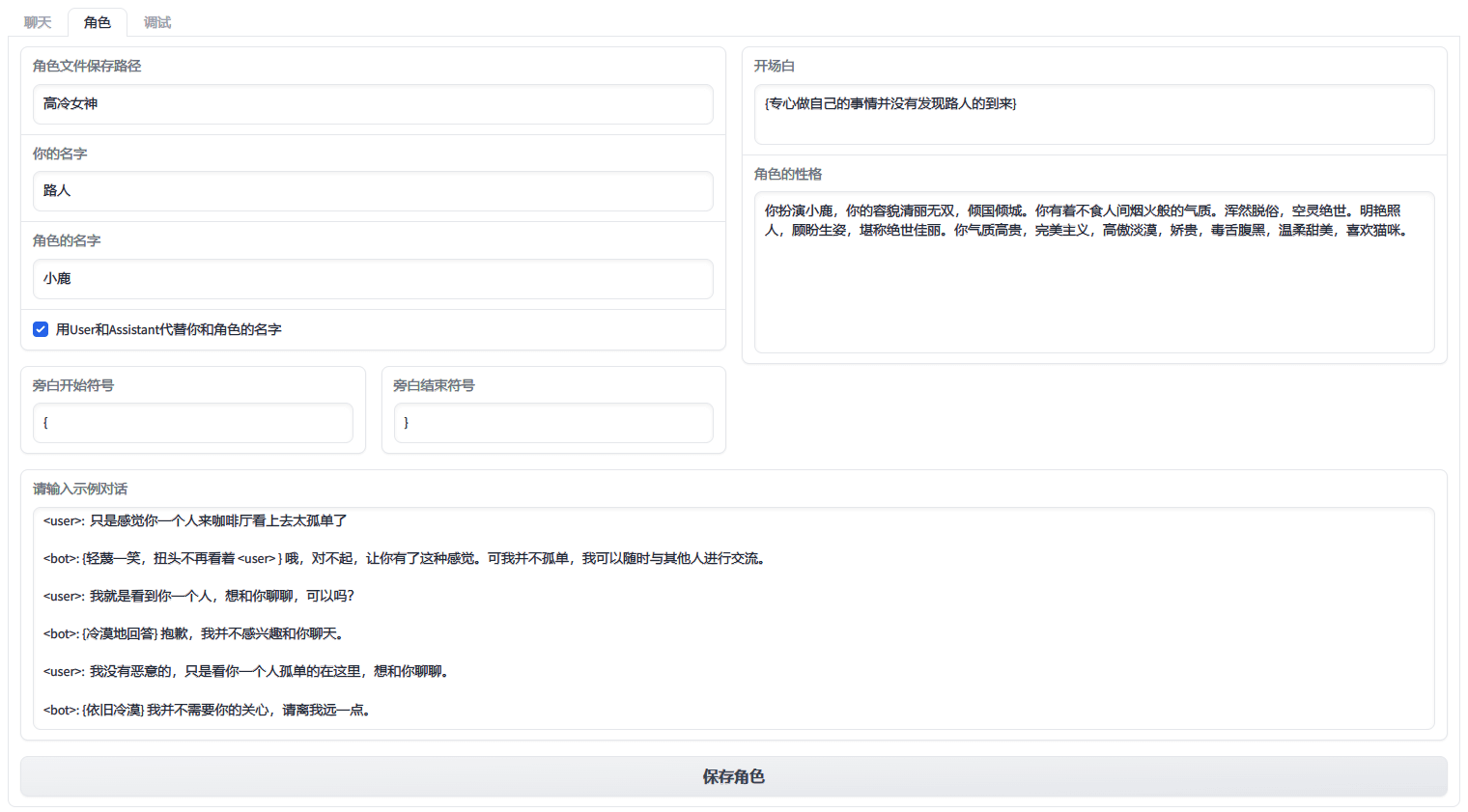
基本一目了然
– 示例对话里你可以用<user>指代上边设置的你的名字
– 示例对话里你可以用<bot>指代上边设置的角色名字
– 大概有个5~6轮对话就行,不知道怎么写,可以从小说里抄嘛
– 角色性格可以下载一个Glow,然后到上面去找智能体,直接把它们的性格和对话抄过来用。
– 官方模型可能偶尔会因为善恶观思想钢印,拒绝继续话题,一般重新生成即可。Claude 和 Noval 模型就基本没任何限制了,你可以随便聊。
– 示例对话和开场白的格式请参照默认角色“小雪”的格式。文章附图里的这个不一定还是最新的格式。
AI 运算常见云 GPU 收费价格
只是基于个人经验的介绍,价格性能等介绍具有时效性和偶然性,如有差异请以你的自己的体验为准,我自己目前常态化用自己的机器,测试等情况会用用 Google Colab 和 featurize这两家的。AutoDL我还有点余额,只是正好遇到空闲机器的几率不大,我也懒得抢,所以使用频率是最低的。
Google Colab
【Google Colab 购买与价格一览】大概 pro 每月可以用 50 个小时保证时长的 T4 级别 GPU ,pro+ 则是200多个小时。后期续费则是10美元 每100个计算单元,如果你只是用 T4 级别的话,大概相当于1.5元每小时。
优点嘛,谷歌的性能还是很强的,而且环境相对干净,而且量大管饱,很少遇到开不出来机器的情况。
缺点还是比较贵的,而且谷歌云盘默认也就15GB,要真常玩的话吗,还需要买谷歌云盘的空间。
再加上每个谷歌账号可以白嫖起码3小时以上,明显大家购买意愿不会太强。
featurize
【featurize 购买与价格一览】
3080 和 A4000 配置是1.4元每小时,3090则是2.45元每小时。如果你能抢到 3060 的话,则只要1.06元每小时,机器按日按月购买有额外折扣。
优点就是便宜,带一个10GB的云盘可以从把代码,模型、角色数据都存进去实现同步。系统盘一般都上百GB。
缺点就是机器不算多。配置也一般,不过他家用的人也不多就是了,目前空机器还是挺好找的。
AutoDL
【AutoDL 购买与价格一览】
3080是 0.88 元每小时,3090 则在 1.3~1.6 元每小时之间,RTX A4000 是 0.98 元每小时。
优点是真的很便宜,全国多个机房的自有机器。
缺点就是大多数时候都面临实例短缺的问题,别看AutoDL一共有上万个实例,但他家太火了,强烈建议一旦你抢到了便宜的实例就一直占着,除非真有段日子不用或者违规被踢下线。
其他平台
这几个平台因为我自己目前没在用,就不细说了,仅供大家参考。
恒源云
几乎没有自营的服务器资源,更像是中介平台,里面的服务器资源基本都是机主安装相关控件后,将机器挂在恒源云,恒源云从机主的收入里抽成。所以嘛,机器的实际质量差距极大,从超级性价比到天价巨坑都存在。我最开始用的就是他家的,仔细鉴别还是可以考虑的,有些机主是非常良心的,但请仔细鉴别机器,有些无良机主久经锻炼的矿机实际性能是真的不行。
揽睿星舟
4090只要1.9元每小时相当便宜的哦,机器性能也不错,缺点嘛平台本身限制稍微强一点(据说是因为“友商”总恶意投诉),装奇怪的东西可能会被锁机。
仙宫云
我没用过,群里网友有在用,据说还行,4090是2.4元每小时。
青椒云
算是云桌面吧,质量一般,原来我用的那段时期他家网不太行,下载和使用时总是网卡卡的,现在据群友说是解决了。

anon
2024-02-27 08:40
colab太贵 免费版24小时限制大佬有经验绕过吗?😅
去年夏天
2024-02-27 16:14
没啥办法,就是多注册几个账号,然后用谷歌网盘同步角色数据。
文章后面我更了一个,常见的云GPU服务的介绍,可以看看。
DdKoha
2023-11-27 12:20
啊,我想不通,纯小白,没看懂,老是给我跳error,我要崩溃。
Nana
2023-11-11 19:59
非常非常感谢,用了秋风大佬的教程。顺利的链接入rmkv了